쿠버네티스에서 모니터링을 구성할 때 대부분 Prometheus로 시작한다.
하지만 클러스터와 서비스가 늘어나면 곧 다음 질문에 부딪힌다.
“Prometheus 메트릭을 몇 달~몇 년 보관하려면 어떻게 해야 하지?”
이 글에서는 Prometheus 장기 저장을 위한 대표적인 두 솔루션
Thanos 와 Grafana Mimir 를 중심으로
- 각각 무엇인지
- 구조적 차이
- 어떤 상황에서 적합한지
- Prometheus 단독과 비교
- 리소스 사용 관점의 차이
를 쿠버네티스 기준으로 정리한다.
1. Prometheus 단독의 한계
Prometheus는 기본적으로 로컬 TSDB(Local Disk) 기반이다.
장점
- 설치/운영 단순
- Kubernetes 생태계 표준
- 빠른 쿼리 성능
한계
- 장기 보관(수개월~수년)에 부적합
- 디스크 비용 증가
- 단일 인스턴스 병목
- 멀티 클러스터 / 글로벌 쿼리 / HA 구성 복잡
👉 이 한계를 해결하기 위해 등장한 것이 Thanos와 Mimir다.
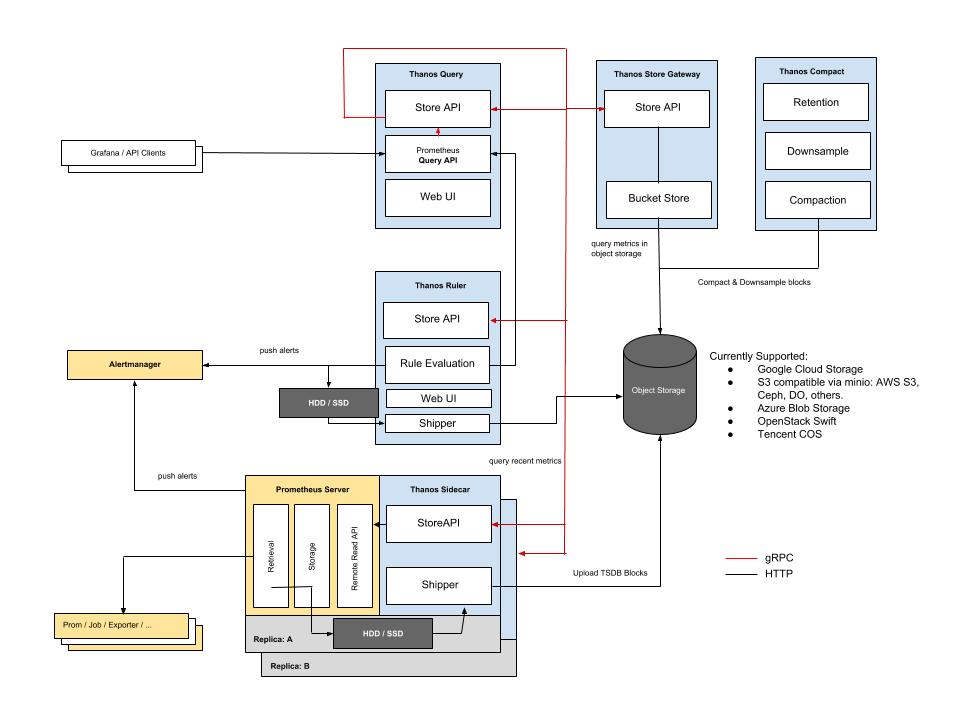
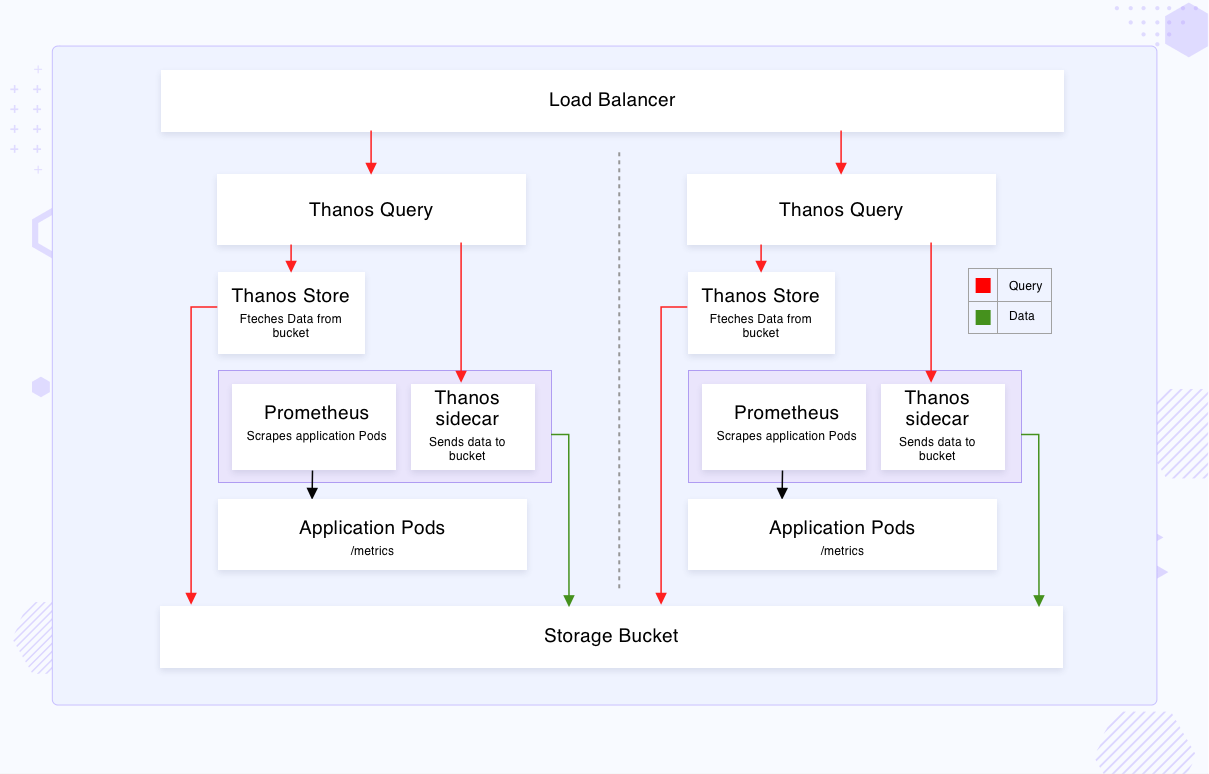
2. Thanos란 무엇인가
!https://thanos.io/v0.6/img/arch.jpg
{kind=link}
{kind=link}
개념 요약
Thanos는 Prometheus를 그대로 유지하면서
장기 저장 + 글로벌 쿼리 + HA를 제공하는 확장 레이어다.
핵심 구조
- Prometheus + Thanos Sidecar
- TSDB 블록을 Object Storage(S3/GCS/Azure Blob) 로 업로드
- Thanos Query가 여러 Prometheus/스토리지를 하나로 조회
- Deduplication으로 HA Prometheus 처리
특징
- PromQL 100% 호환
- 기존 Prometheus 설정 변경 최소
- 단계적 도입이 쉬움
- “Prometheus 중심” 구조 유지
언제 적합한가
- 이미 Prometheus를 잘 운영 중
- 멀티 클러스터 메트릭을 한 Grafana에서 보고 싶을 때
- 장기 보관(수개월~1년 이상)이 필요할 때
- 운영 복잡도를 급격히 올리고 싶지 않을 때
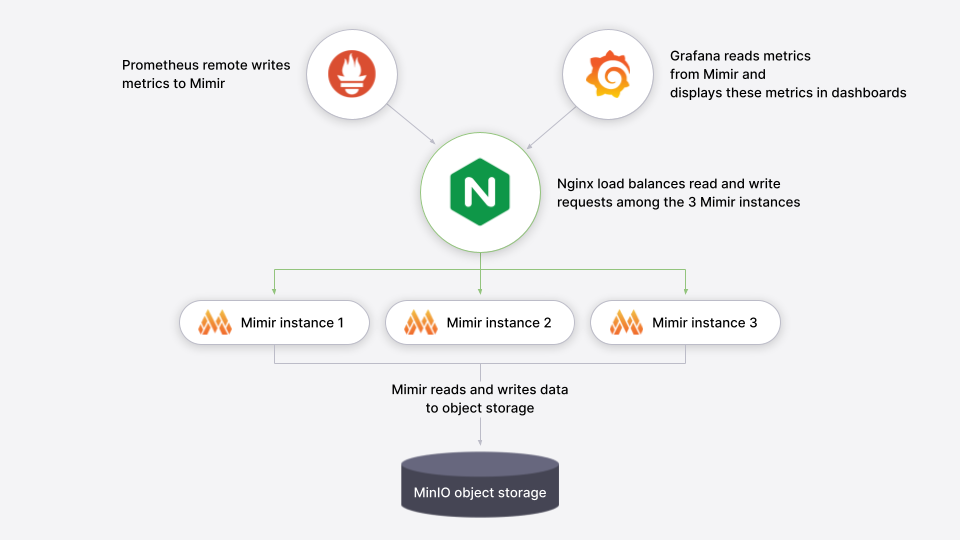
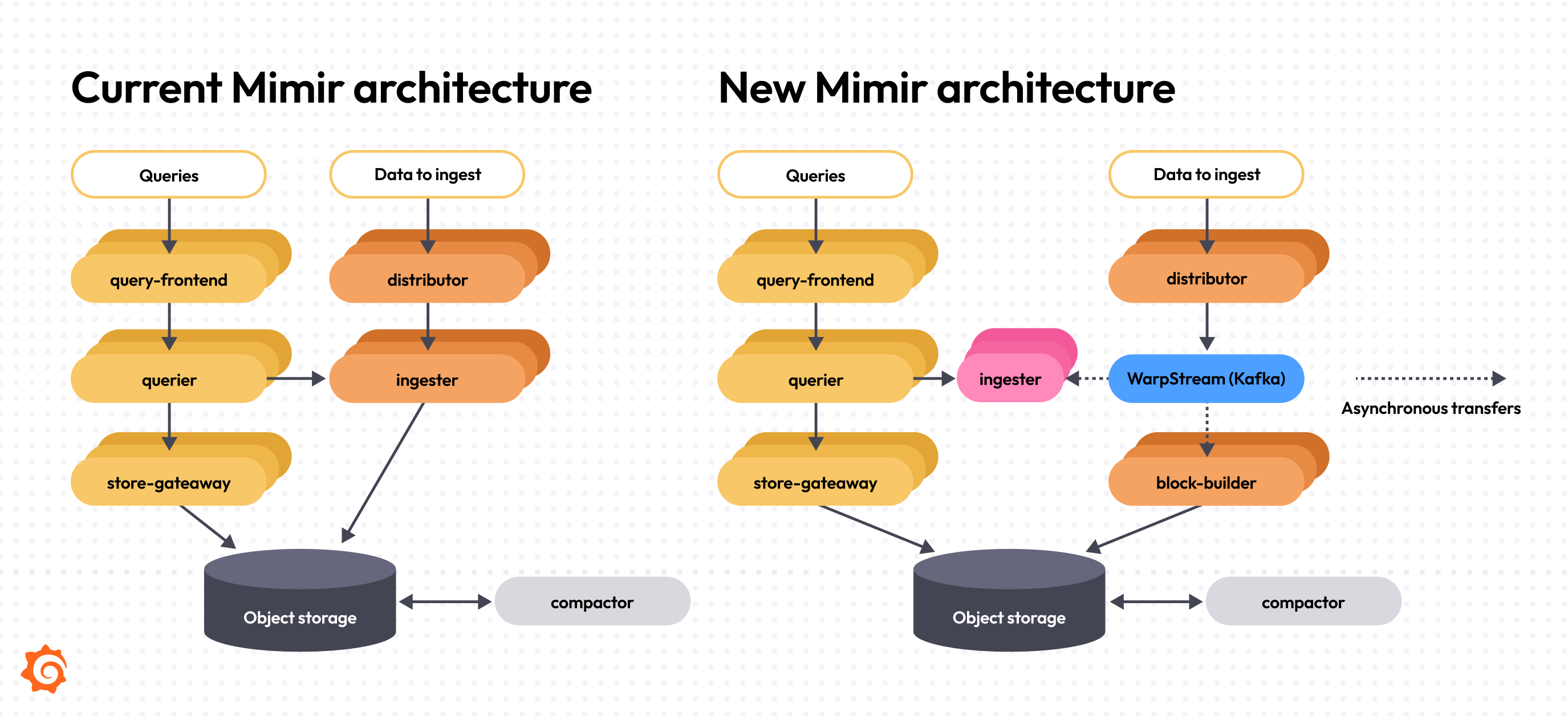
3. Grafana Mimir란 무엇인가
!https://grafana.com/tutorials/play-with-grafana-mimir/tutorial-architecture.png
{kind=link}
!https://s3.amazonaws.com/a-us.storyblok.com/f/1022730/e2ac62d4ff/mimir-architecture-diagram3.png
{kind=link}
개념 요약
Mimir는 Prometheus 메트릭을 받아 저장하는 중앙 메트릭 백엔드다.
Prometheus는 더 이상 “저장소”가 아니라
👉 스크레이퍼 + 에이전트 역할에 가깝다.
핵심 구조
- Prometheus → remote_write
- Mimir:
- Distributor (ingest)
- Ingester
- Querier
- Store Gateway
- Object Storage 기반 장기 저장
- 완전한 수평 확장 구조
특징
- Prometheus 호환 (PromQL 유지)
- 멀티테넌시가 핵심 기능
- 쿼터, 레이트 리밋, 테넌트 격리
- 대규모 조직/플랫폼에 적합
언제 적합한가
- 클러스터/팀/서비스가 매우 많음
- 중앙 Observability 플랫폼이 필요
- 팀별 메트릭 격리/비용 분리 필요
- Prometheus 단독으로는 한계가 명확한 단계
4. Thanos vs Mimir 핵심 차이
| 구분 | Thanos | Grafana Mimir |
| 기본 포지션 | Prometheus 확장 | 중앙 메트릭 플랫폼 |
| 저장 방식 | TSDB 블록 업로드 | remote_write 수집 |
| Prometheus 역할 | 핵심 저장 주체 | 수집 에이전트 |
| 멀티테넌시 | 제한적 | 강력 (1급 기능) |
| 도입 난이도 | 낮음 | 중~높음 |
| 스케일 전략 | 조회/스토리지 분리 | 완전 분산 수평 확장 |
| 추천 규모 | 중소~중대형 | 대형/조직형 |
5. 리소스 사용 관점 비교
⚠️ 실제 수치는 active series 수 / 카디널리티 / 쿼리 패턴에 따라 크게 달라진다.
아래는 경향성이다.
Prometheus 단독
- CPU/메모리: scrape + rule + query 집중
- 디스크: retention 증가 시 급격히 증가
- 규모 커질수록 병목 빨리 도달
Thanos
- Prometheus 리소스: 거의 동일
- 추가 리소스:
- Sidecar: 경량
- Query / Store: 조회 많을수록 증가
- Compactor: 주기적 CPU/IO 사용
- 장기 저장 부담은 Object Storage로 분산
Mimir
- Prometheus 부담 감소 (remote_write만)
- Mimir 자체가 항상 돌아가는 분산 시스템
- 소규모에선 오버헤드 체감
- 대규모에선 가장 예측 가능한 확장성
6. 쿠버네티스 규모별 추천 조합
소규모 (1~2 클러스터, 7~30일)
- ✅ Prometheus 단독
중간 규모 (여러 클러스터, 3~12개월)
- ✅ Prometheus + Thanos
대규모 / 조직형
- ✅ Prometheus + Grafana Mimir
7. 선택 기준 한 줄 요약
- “Prometheus 유지 + 장기 저장” → Thanos
- “중앙 메트릭 플랫폼 + 멀티테넌시” → Mimir
- “단순하고 가볍게” → Prometheus 단독
마무리
Thanos와 Mimir는 경쟁 관계라기보다, 지향점이 다른 도구다.
- Thanos는 Prometheus를 확장하는 도구
- Mimir는 Prometheus 위에 세우는 플랫폼
현재 클러스터 규모보다
👉 1~2년 뒤 조직과 서비스 성장 방향을 기준으로 선택하는 것이 가장 중요하다.
'K8S' 카테고리의 다른 글
| Kubernetes Pod 부팅 스파이크, 어떻게 해결할까? (0) | 2026.01.15 |
|---|---|
| Kubernetes v1.35 변화 정리 (0) | 2026.01.15 |
| k9s 사용법 - v.50.x (1) | 2025.12.31 |
| kubernetes의 Request (0) | 2025.12.23 |
| Kubernetes HPA 설계, 웹 API는 정말 CPU-Only가 표준일까? (0) | 2025.12.02 |
댓글