aws glue 를 사용해보려고
자습서를 찾는데(aws glue docs에도 있긴하다)
aws glue 서비스내에 자습서가 있음...
크롤러 추가
출발 공항의 인기도를 월별로 계산하기 위해 주요 항공사의 도착 데이터를 분석하라는 요청을 받았다고 가정합니다. 2016년도 항공편 데이터가 CSV 형식으로 Amazon S3에 저장되어 있습니다. 데이터를 변환하기 전에 AWS Glue 데이터 카탈로그에 해당 메타데이터를 카탈로깅합니다.
Amazon S3에 저장된 이들 항공편 로그에서 메타데이터를 추론하는 크롤러를 추가하고 데이터 카탈로그에 테이블을 생성해 보겠습니다
크롤러 속성 지정
먼저 크롤러 이름을 Flights Data Crawler로 지정합니다.
크롤러는 분류자를 호출하여 데이터의 스키마를 추론합니다. 이 자습서에서는 CSV에 기본 제공 분류자를 사용합니다. 경우에 따라 사용자 지정 분류자를 선택할 수 있습니다.
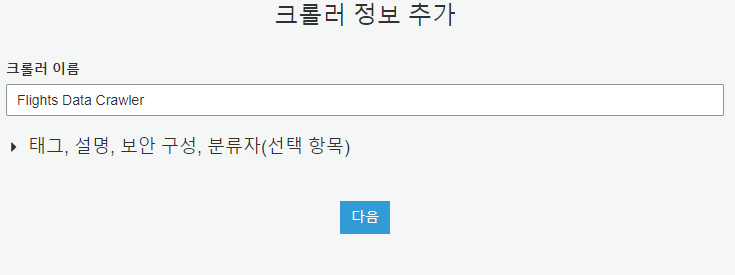
크롤러 원본 유형 지정
데이터 스토어 선택
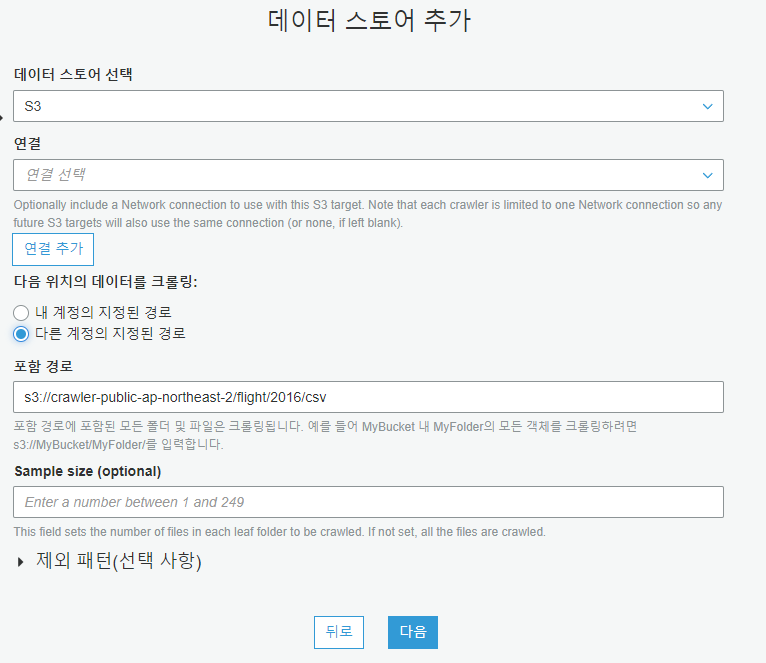
다른 데이터 스토어 추가
아니요를 선택합니다.

IAM 역할 생성
그러면 크롤러가 실행 및 S3 데이터 스토어 액세스에 사용하는 AWSGlueServiceRole-DefaultRole이라는 이름의 IAM 역할이 생성됩니다.

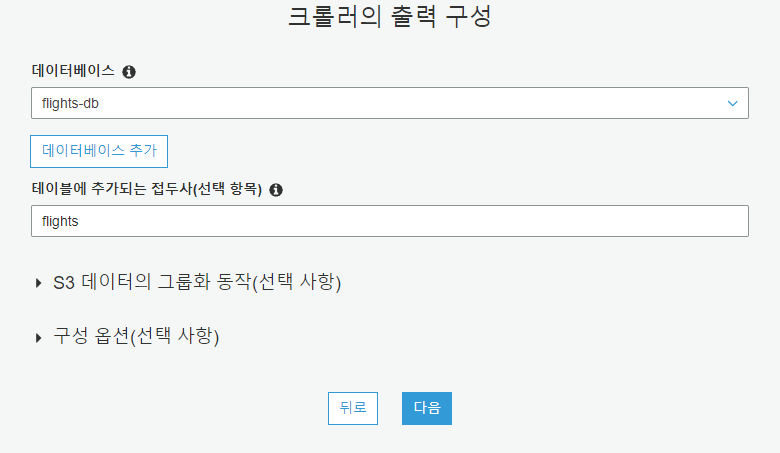
테이블 위치 지정
테이블에 추가되는 접두사로 flights를 입력합니다.
다음을 선택합니다.
크롤러 실행
축하합니다! 데이터 카탈로그에서 크롤러를 정의하고 한 번 실행하여 데이터 카탈로그에서 메타데이터 테이블을 생성했습니다.
다음 자습서 "테이블 탐색"으로 이동합니다.
모든 테이블 나열
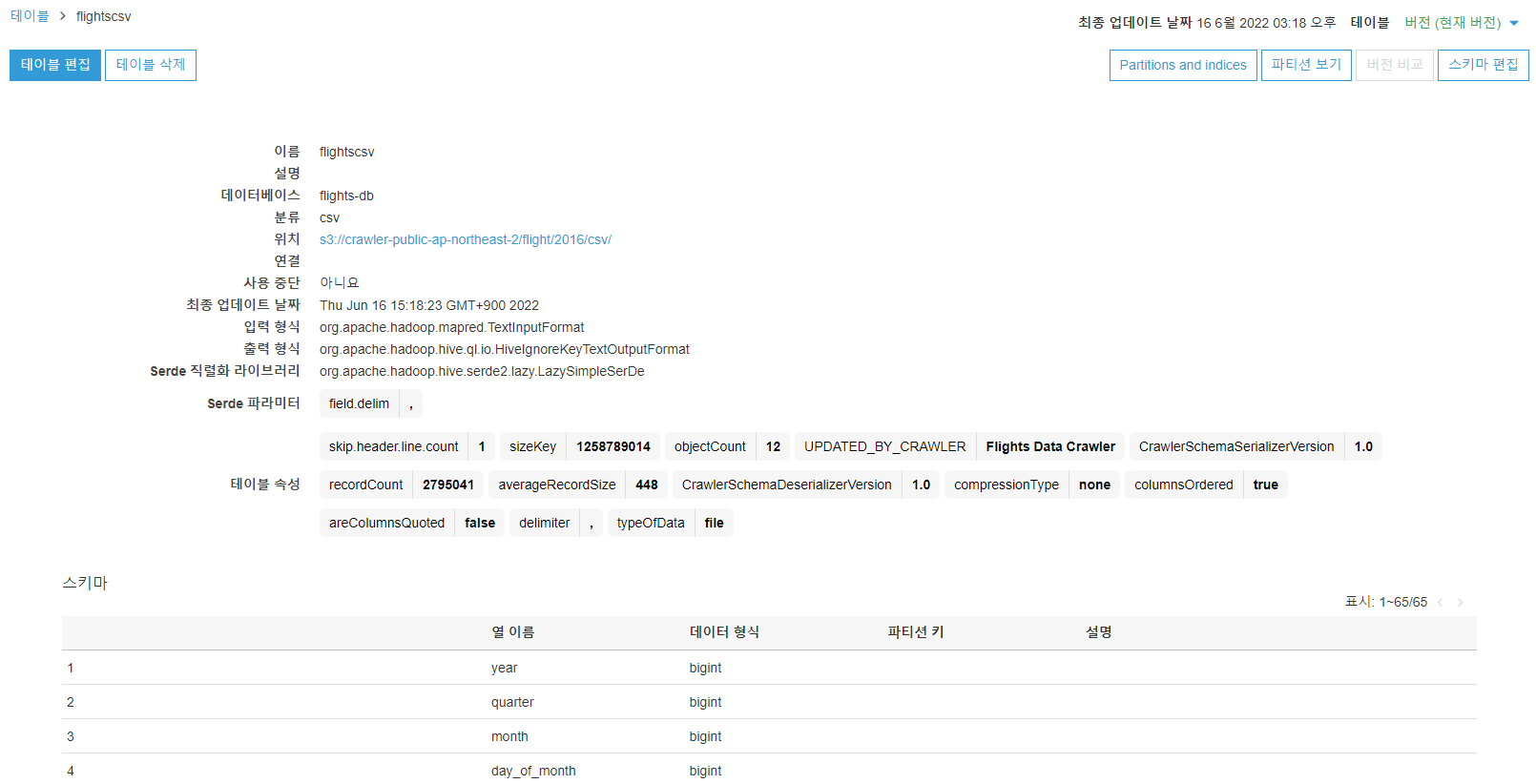
크롤러가 데이터 카탈로그에 추가한 테이블을 보고 수정해 보겠습니다. 테이블 목록에는 데이터 카탈로그 내 모든 테이블이 표시됩니다.
테이블 찾기
테이블에 대한 자세한 내용을 보려면 테이블을 이름을 참조합니다.
테이블에 대한 자세한 내용을 보려면 작업 > 세부 정보 보기를 선택합니다

테이블 세부 정보 보기
계속하려면 파티션 보기를 선택합니다.
파티션 보기
파티션 중 하나의 속성을 보려면 다음을 선택합니다.
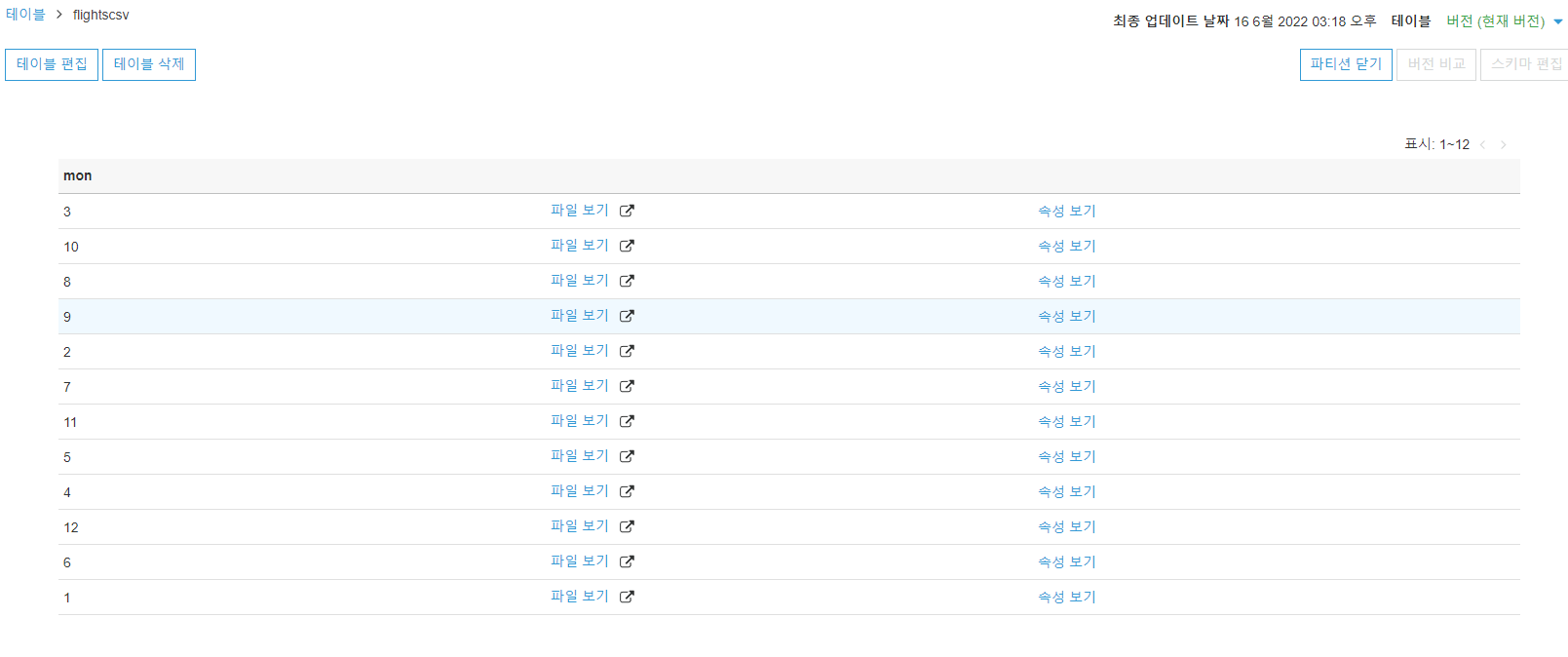
속성 보기
속성 페이지를 닫고 파티션을 닫은 후, 스키마 편집을 선택합니다.

스키마 편집
저장을 선택하고 버전 비교를 선택합니다.

버전 비교
버전 비교를 중지하고 다음 자습서 작업 추가로 진행합니다.

작업 추가
다음으로 CSV 파일을 Parquet 형식으로 변환하고, 데이터 분석이 필요 없는 필드는 삭제합니다.
ETL 작업을 생성하여 항공편 데이터의 해당 열을 Amazon S3 소스에서 Amazon S3 대상으로 추출, 변환 및 로드해 보겠습니다.

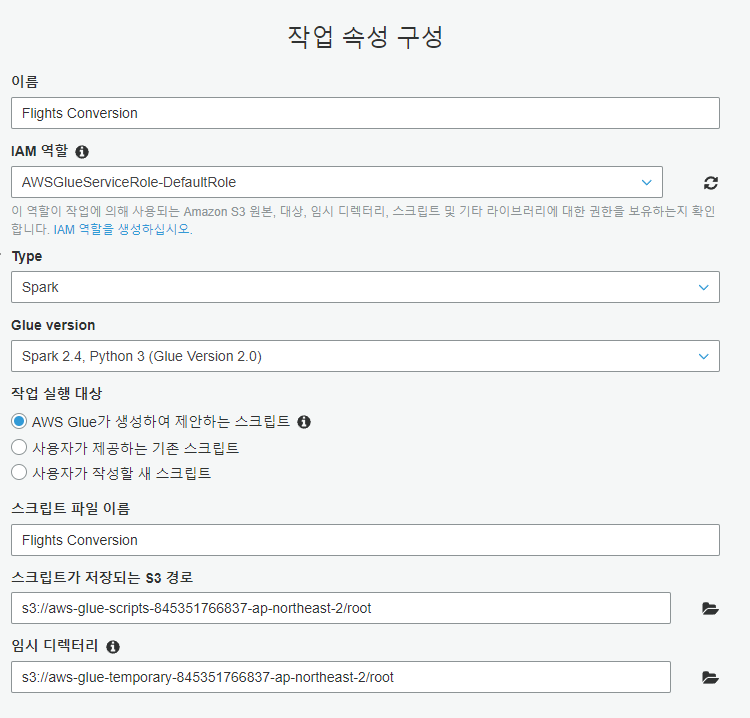
작업 속성 지정
"AWS Glue가 생성하여 제안하는 스크립트"를 선택하고 스크립트 파일 이름, tutorial-script 및 스크립트가 저장되는 S3 경로를 입력하여 AWS Glue에서 스크립트를 생성하게 합니다. 또한 S3에서 임시 디렉터리를 선택합니다.
데이터 소스 선택

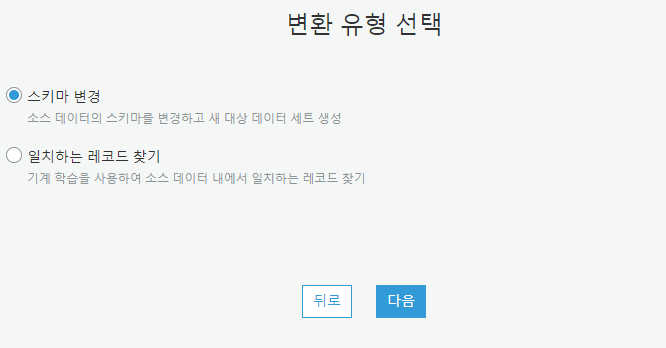
변환 유형 지정
여기에서 소스 데이터를 변환하는 방법을 선택할 수 있습니다. 스키마 변경을 선택하여 데이터 유형을 변환하고 기존 데이터 세트의 필드 이름을 바꾸고 재정렬합니다.
데이터 대상 선택

소스 스키마를 대상으로 매핑
"x" 작업을 선택하여 대상 테이블에서 first_dep_time, total_add_gtime 및 longest_add_gtime 열을 제거합니다. 이들 열은 출발 공항의 공항 게이트 반환 정보에 해당하며 데이터 분석 대상에는 포함되지 않습니다.
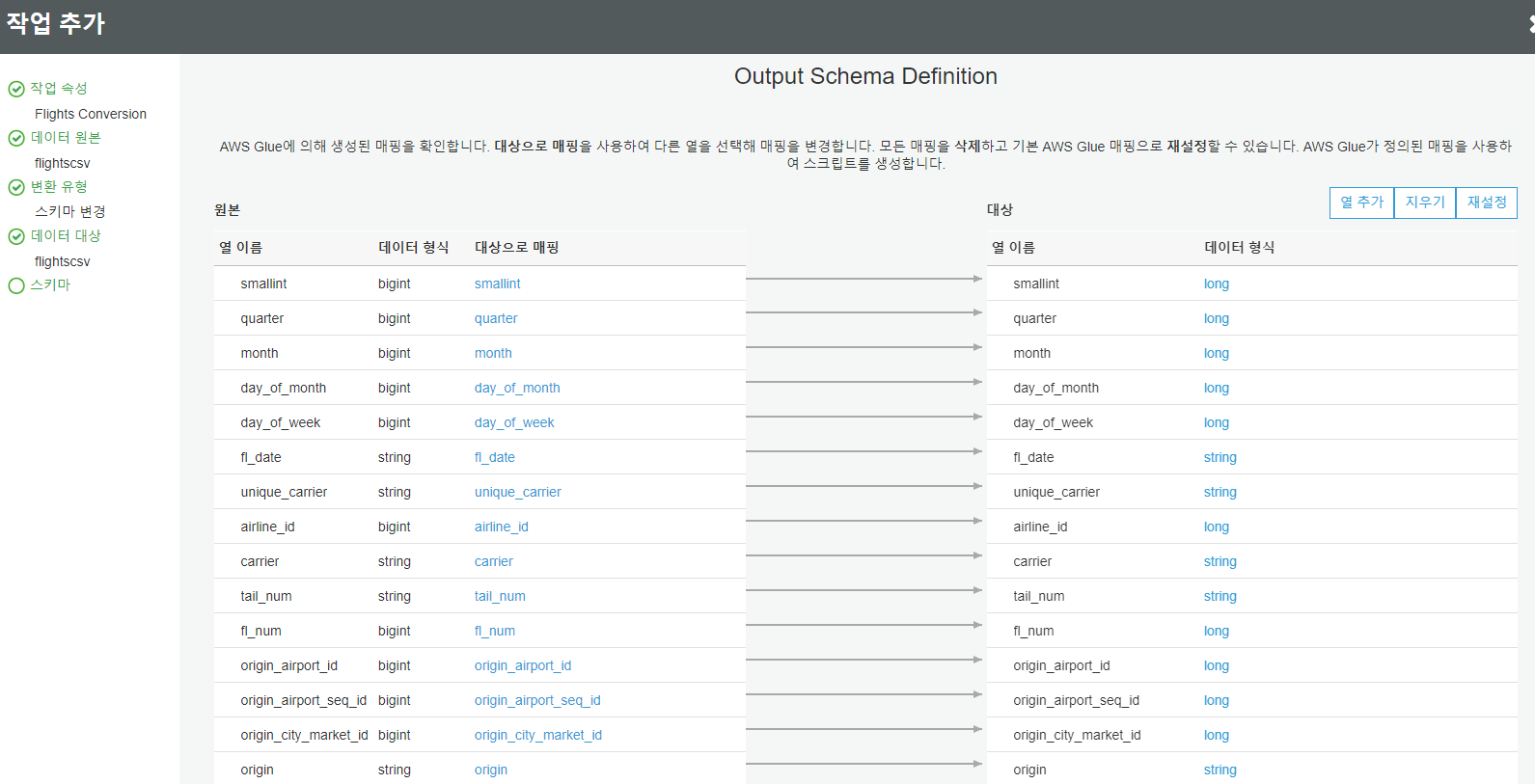
생성된 스크립트 및 다이어그램 보기
필요에 따라 스크립트를 수정할 수 있습니다. 이 편집기에서는 원본, 대상 및 변형 추가에 사용할 코드 템플릿을 제공합니다.
파라미터 검토 및 작업 실행
작업이 실행 중입니다.
이 작업의 로그 메시지는 실행 과정에서 로그 탭에 표시됩니다.
작업이 완료되면 작업 목록 페이지에 작업에 관한 최신 통계가 표시됩니다. 작업을 여러 번 실행하는 경우 기록 탭을 참조하여 작업 및 액세스 오류 로그의 특성을 이해하는 데 도움이 됩니다.
작업이 성공적으로 실행되면 대상 S3 폴더로 이동하여 parquet 형식으로 변환된 항공편 데이터를 확인합니다.

parquet
https://butter-shower.tistory.com/245
[pyspark/빅데이터기초] Parquet(파케이) 파일 형식이란?
파케이(parquet)이란 하둡에서 칼럼방식으로 저장하는 저장 포맷을 말합니다. 파케이는 프로그래밍 언어, 데이터 모델 혹은 데이터 처리 엔진과 독립적으로 엔진과 하둡 생태계에 속한 프로젝트
butter-shower.tistory.com
glue크롤러를 이용하여 parquet 파일 쿼리
https://ahana.io/answers/query-parquet-using-amazon-athena/
How to Query Parquet Files using Amazon Athena | Ahana
Here are steps to quickly get set up to query your parquet files with a service like Amazon Athena.
ahana.io
'CLOUD > AWS' 카테고리의 다른 글
| aws step function (0) | 2022.06.23 |
|---|---|
| AWS codestar (2) | 2022.06.22 |
| [awsblog]exponential backoff (0) | 2022.06.15 |
| aws firehose (0) | 2022.06.14 |
| cloudwatch log flow 의 iam 역할 (0) | 2022.06.14 |

댓글