아래내용은 아래 사이트 번역한것입니다.
번역기를 돌려 이상할수 있으니 영어가 되신다면 아래 사이트를 보시는게 좋을것같습니다.
https://www.educative.io/answers/what-is-the-docker-container-lifecycle
What is the Docker container lifecycle?
Contributor: abhilash
www.educative.io
이 게시물은 사이공의 grokking 엔지니어링 커뮤니티 와 공동 이벤트의 기초였습니다 .
이 이벤트는 DevOps를 중심으로 진행되었습니다. 토론에서 Docker Saigon은 Docker 내부에서 작동하는 방식에 대해 엔지니어링 청중의 관심을 끌 필요가 있었습니다. Docker 및 Linux 운영 체제에 대한 청중 경험이 필요했습니다.
Docker에 대해 자세히 알고 싶은 사람이라면 누구나 3월 23일 ⁄ 24 일 에 전체 무료 실습 교육 이벤트를 진행할 예정입니다 . 자세한 내용은 metup.com/Docker-Saigon 으로 이동하십시오.
개요
- Linux 컨테이너 개요
- Linux 컨테이너란 무엇이며 Linux 컨테이너에 대한 몇 가지 역사입니다. 패키지 관리자, 구성 관리 ...와 어떤 관련이 있습니까?
- 그들은 어떻게 작동합니까?
- 네임스페이스, cgroup, 이미지, 레이어 및 기록 중 복사
- 컨테이너 런타임 개요
- 과거, 현재, 미래
- 도커 API
- 이벤트 및 후크에 중점
- 컨테이너 형식 폭발
- 공통 표준을 향한 진화?
Linux 컨테이너 개요
이 섹션의 목표는 Linux 시스템 관점에서 컨테이너에 대한 매우 짧은 개요를 제공하는 것이며 Docker에 익숙하지 않은 사용자나 Linux 시스템에 익숙하지 않은 사용자를 소개하기 위한 것이 아닙니다.
Docker를 시작하는 방법에 대해 자세히 알아보려는 Saigon의 개발자는 Docker 웹 사이트에서 제공 되는 우수한 설치 가이드(OSX/Windows) 및 사용자 가이드 를 참조하십시오.
Docker가 중요한지 여부/이유를 궁금해하는 사람은 Docker Saigon 사용자 그룹에 연락하여( 가급적이면 Slack 자동 초대 앱 을 통해 ) 토론을 요청하십시오.
컨테이너 란 무엇입니까?
4개의 글머리 기호:
- 컨테이너는 호스트 커널을 공유합니다.
- 컨테이너는 커널 기능을 사용하여 리소스 제어를 위해 프로세스를 그룹화합니다.
- 컨테이너는 네임스페이스를 통해 격리를 보장합니다.
- 컨테이너는 경량 VM처럼 느껴지지만(더 적은 공간, 더 빠른) 가상 머신은 아닙니다!
컨테이너 생태계 의 구성 요소는 다음과 같습니다.
- 실행 시간
- 이미지 배포
- 압형
이제... Linux를 보면 kernel컨테이너와 같은 것이 없습니다. 그래서 무엇을 제공합니까?
컨테이너 기술의 역사
- 1982년경 Chroot
- 2000년경 FreeBSD 감옥
- 2004년경 Solaris 영역
- Meiosys - 체크포인트/복원 기능이 있는 메타클러스터 2004-05
- 2005년경 Linux OpenVZ(주류 Linux에는 없음)
- 2007년경 AIX WPAR
- 2008년경 LXC
- 2010-2013년경 Systemd-nspawn
- 2013년경 도커
- LXC 기반
- libcontainer 로 이동 (2014년 3월)
- appC (CoreOS) 발표(2014년 12월)
- Docker와의 통합 을 위한 Open Containers 표준 발표(2015년 6월)
- runC (OCF 준수)로 이동(2015년 7월 )
- ... 더 많은 컨테이너 형식이 제공되나요?
컨테이너는 패키지 관리자와 어떻게 비교됩니까?
컨테이너가 패키지 관리와 다른 이유는 무엇입니까?
이미지로 패키징하는 것은 RPM과 유사하지만 Linux 배포판을 제외하고 소프트웨어가 제대로 패키징되는 경우는 거의 없습니다.
Docker의 가장 큰 혁신은 패키지 관리자를 사용하기가 약간 더 쉽다는 것입니다. 패키지 관리자는 종속성 문제를 일으키는 공유 라이브러리 버전 차이로 인해 실패했습니다 . 이미지에 공유 라이브러리를 패키징하면 문제가 해결됩니다.
없어진 물건 있어요?
패키지 관리자는 패키지 내부에 무엇이 있는지 쉽게 찾을 수 있는 방법을 제공합니다. 컨테이너 이미지로 이것을 처리하는 방법이 궁금하시다면…
이미지 검사를 위해 메타 데이터 태그 시스템이 제안된 Dockercon EU 회담 을 참조하십시오 . 선적 목록 , 선하증권, Docker 메타데이터 및 컨테이너 보기 - 비디오
컨테이너는 구성 관리와 어떻게 비교됩니까?
구성 관리 유틸리티는 인프라를 코드로 저장하는 기능을 제공합니다. 인기 있는 CM 도구는 다음과 같습니다.
위의 도구 중 일부는 독립적이고 모든 환경의 동일한 아키텍처에서 정확히 동일한 방식으로 실행되는 패키지를 배포하는 것과는 대조적으로 여전히 절차적으로 환경을 프로비저닝하고 있습니다(환경은 Linux 배포[Ubuntu/redhat/. .], 규모 [로컬 랩톱/서버 클러스터/ ...], ...).
그러나 이러한 프로비저닝 도구를 활용하여 Docker 인프라를 부트스트랩하여 컨테이너 런타임 계층이 준비되면 애플리케이션 계층을 처리하도록 하는 것이 좋습니다.
요약하면 다음 핵심 사항이 Docker 컨테이너의 채택을 주도한다고 생각합니다.
- Docker는 랩톱에서 실행되는 것과 클라우드에서 실행되는 것과 정확히 동일한 이미지인 자체 포함 이미지를 제공하는 반면 Puppet/Chef는 클러스터 시스템을 수렴하기 위해 다시 실행해야 하는 절차적 스크립트입니다. 이를 통해 불변 인프라 또는 피닉스 배포라고도 하는 접근 방식을 사용할 수 있습니다.
- Docker는 정말 빠르며 컨테이너를 세우는 데 몇 초가 걸립니다! 고밀도를 가능하게 하는 오버헤드(cpu, 메모리, io, ..)가 거의 없습니다(예: 랩톱에서 전체 컨테이너 스택 실행, Puppet/Chef를 사용하는 경우 다음을 사용하여 여러 VM을 만들어야 합니다. 훨씬 더 무거운 발자국).
- 커뮤니티는 이미지를 빌드하는 방법이 쉽기 때문에 Docker를 빠르게 채택했습니다. Dockefile DSL 은 매우 간단하고 강력합니다(순수한 bash를 사용하여 이미지를 빌드하거나 load python 스크립트 또는 유사한 것을 사용할 수 있습니다. 기계 구성.
왜 도커인가?
Docker는 현재 전체 패키지를 제공하는 유일한 생태계입니다.
- 이미지 관리
- 리소스 격리
- 파일 시스템 격리
- 네트워크 격리
- 변경 관리
- 나누는
- 공정 관리
- 서비스 검색(DNS 1.10 이후)
어떻게?
이 섹션의 목표는 Linux 컨테이너를 가능하게 하는 Linux 스택의 각 구성 요소를 매우 자세히 살펴보는 것입니다.
더 높은 수준의 개요는 공식 Docker 문서 에서 사용할 수 있습니다(참조로 사용됨 ) .
업데이트: jfrazelle's talk @ container Summit 2016년 2월 참조
커널 네임스페이스
다음을 격리할 수 있습니다.
- 프로세스 트리(PID 네임스페이스)
- 마운트(MNT 네임스페이스)wc -l /proc/mounts
- 네트워크(네트 네임스페이스)ip addr
- 사용자/UID(사용자 네임스페이스)
- 호스트 이름(UTS 네임스페이스)hostname
- 프로세스 간 통신(IPC 네임스페이스)ipcs
- IPC = PostgreSQL을 사용한 주목할만한 예
씨그룹
커널 제어 그룹(cgroup)을 사용하면 프로세스에서 사용하는 리소스에 대한 계정, 장치 노드에 대한 약간의 액세스 제어 및 프로세스 그룹 고정과 같은 기타 작업을 수행할 수 있습니다.
참조 DockerCon EU: jpetazzoni: 컨테이너는 무엇으로 만들어졌습니까? 이 훌륭한 프레젠테이션에 대한 요약된 개요를 여기에 제공하려고 합니다.
cgroup은 리소스(cpu, 메모리, …)당 하나의 계층 구조(트리)로 구성됩니다. 예를 들어:
cpu memory
├── batch ├── 109
│ ├── hadoop ├── 88 <
│ │ ├── 88 < ├── 25
│ │ └── 109 ├── 26
└── realtime └── databases
├── nginx ├── 1008
│ ├── 25 └── 524
│ └── 26
├── postgres
│ ├── 524
└── redis
└── 1008
위의 예에서 리소스에 대한 사용자 지정 batch및 realtime하위 그룹 이 생성 된 것처럼 각 계층에 대한 하위 그룹을 생성할 수 있습니다 . cpu각 프로세스는 각 리소스에 대해 1개의 노드에 있습니다( pid88은 메모리 리소스와 CPU 리소스에 대한 노드에 있습니다. …)
참고: cgroup은 시스템 전체에 적용됩니다 . 이 기능은 부팅 시 활성화/비활성화되며 프로세스 수준별로 제어할 수 없습니다.
각 리소스 트리를 자세히 살펴보면 다음과 같습니다.
메모리 cgroup:
메모리 리소스는 회계, 제한 및 알림의 3가지 유형의 기능을 제공합니다.
회계
세분성 = 메모리 페이지 크기(아키텍처에 따라 4kb)
2가지 유형의 메모리 페이지:
- 파일 페이지 : 디스크에서 로드됨(데이터가 여전히 디스크에 있고 메모리에서 제거될 수 있다는 것을 알고 있기 때문에 중요, 메모리를 회수해야 할 때 스왑할 필요 없음)
- 익명 페이지 : 디스크의 어떤 것과도 일치하지 않는 메모리, 이 유형의 경우 이 메모리를 회수하려면 교체해야 합니다.
일부 페이지는 공유될 수 있습니다. 예를 들어, 동일한 파일에서 읽는 여러 프로세스.
모든 페이지에 대해 2개의 풀을 생성합니다.
- 활동적인
- 비활성 페이지 - 자주 액세스하는 페이지를 활성 세트로 유지합니다.
각 페이지는 그룹으로 간주되고 공유 페이지는 1개의 그룹에만 계산되며 해당 그룹이 사라지면 다른 그룹에 다시 할당됩니다.
제한
각 그룹에는 선택적으로 2가지 유형의 제한이 있습니다.
- 하드 제한 : 그룹이 하드 제한을 초과하면 out of memory오류와 함께 그룹이 종료됩니다. (이것이 컨테이너에 단일 프로세스를 넣는 것이 좋은 방법인 이유입니다)
- 소프트 제한 : 적용되지 않습니다... 시스템에서 메모리가 부족해지기 시작할 때를 제외하고. 프로세스가 소프트 한도를 초과할수록 해당 그룹에 대해 페이지가 회수될 확률이 높아집니다.
제한을 적용할 수 있는 메모리에는 3가지 종류가 있습니다.
- 물리적 메모리
- 커널 메모리: 커널을 남용하여 메모리를 할당하는 프로세스를 방지합니다.
- 총 메모리
메모
- 옴 알리미
- 그룹의 프로세스를 정지하고 사용자 공간에 통지하여 한계를 초과하는 그룹을 처리하도록 사용자 프로그램에 제어를 제공하는 메커니즘을 제공합니다. 이 시점에서 알림을 처리하는 프로그램은 컨테이너를 종료하거나 제한을 높이거나 컨테이너를 마이그레이션할 수 있습니다.
- 간접비:
- 커널이 프로세스와 페이지를 주고받을 때마다 카운터가 업데이트됩니다.
거대TBL cgroup
프로세스 그룹별 방대한 페이지 사용량에 대한 설명, 지금은 무시합니다..
CPU cgroup
- 사용자/시스템 CPU 시간을 추적합니다.
- CPU당 사용량 추적
- 제한이 아닌 가중치를 설정할 수 있습니다.
- 왜 제한이 없습니까? 유휴 호스트에서 공유가 낮은 컨테이너는 여전히 CPU의 100%를 사용할 수 있습니다.
CPUSet cgroup
특정 CPU에 그룹 바인딩
에 유용한:
- 실시간 애플리케이션
- CPU당 로컬 메모리가 있는 NUMA 시스템
BlkIO cgroup
프로세스가 직접 IO를 수행하지 않는 한 그룹별로 blckIO의 양을 측정 및 제한합니다. 제한을 설정하면 놀라운 결과가 나타날 수 있습니다.
net_cls 및 net_prio cgroup
커널은 트래픽에만 태그를 지정하며 트래픽 제어를 수행할 책임이 있습니다( tc).
장치 cgroup
액세스 장치 를 읽고 쓸 수 있는 그룹을 제어 합니다. 그룹이 디스크 드라이브에 직접 읽고 쓰는 것을 방지하는 데 사용할 수 있으며 컨테이너에 매우 중요합니다.
일반적으로 컨테이너 액세스 /dev/{tty,zero,random,null}는 허용되고 다른 모든 것은 거부됩니다.
왜 /dev/random? 컨테이너 내부에서 암호화 키를 생성하는 경우 호스트에서 읽지 않는 한 엔트로피가 빠르게 고갈되기 때문입니다.
컨테이너에 대한 기타 흥미로운 장치:
- /dev/net/tun호스트를 오염시키지 않고 컨테이너 내부의 VPN으로 무엇이든 하고 싶다면
- /dev/fuse컨테이너의 사용자 정의 파일 시스템
- /dev/kvm가상 머신이 컨테이너 내에서 실행되도록 허용
- /dev/dri& /dev/video컨테이너의 GPU 액세스 - ( NVIDIA/nvidia-docker 참조).
냉동실 cgroup
그룹에 전송하지 않고 전체 그룹을 고정합니다 SIGSTOP/SIGCONT(프로세스를 방해하지 않고).
에 유용한:
- 클러스터 배치 스케줄링
- 프로세스 마이그레이션 - CRIU 생각
- prtrace에 영향을 주지 않고 디버깅
Systemd로 cgroup을 관리하는 방법은 무엇입니까?
ControlGroupAttribute단위 파일에서 설정하여 :
.include /usr/lib/systemd/system/httpd.service
[Service]
ControlGroupAttribute=memory.swappiness 70
또는 다음을 통해 실행 중인 프로세스에서 일시적 으로:
systemctl set-property <group> CPUShares=512
기존 그룹의 모든 속성을 표시하려면:
systemctl show <group>
위의 명령은 Docker 데몬 뒤에 있으며 예기치 않은 동작이 발생할 수 있습니다(예: 컨테이너를 다시 시작할 때 설정이 되돌려짐).
참고: Docker 1.10에는 docker update특정 속성에 대한 cgroup 제한을 즉시 변경하는 명령이 도입되었습니다.
Usage: docker update [OPTIONS] CONTAINER [CONTAINER...] Updates container resource limits --blkio-weight=0 Block IO (relative weight), between 10 and 1000 --cpu-shares=0 CPU shares (relative weight) --cpu-period=0 Limit the CPU CFS (Completely Fair Scheduler) period --cpu-quota=0 Limit the CPU CFS (Completely Fair Scheduler) quota --cpuset-cpus="" CPUs in which to allow execution (0-3, 0,1) --cpuset-mems="" Memory nodes (MEMs) in which to allow execution (0-3, 0,1) -m, --memory="" Memory limit --memory-reservation="" Memory soft limit --memory-swap="" Total memory (memory + swap), '-1' to disable swap --kernel-memory="" Kernel memory limit: container must be stopped
커널은 cgroup을 어떻게 노출합니까?
그룹은 의사 파일 시스템을 통해 생성 되며 다음과 systemctl같이 구성 변경 사항이 적용됩니다.
mkdir /sys/fs/cgroup/memory/somegroup/subcgroup
tasks프로세스를 이동하려면 그룹 경로에 있는 특수 파일에 프로세스 ID를 에코하면 됩니다 .
echo $PID > /sys/fs/cgroup/.../tasks
IPTables(네트워킹)
네트워킹 수준에서 격리는 Linux 커널에서 가상 스위치 생성을 통해 이루어집니다. Linux Bridge는 2.2 커널(2000년경)에 처음 도입된 커널 모듈입니다. brctl그리고 Linux에서 명령을 사용하여 관리됩니다 .
Linux 브리지는 Linux 가상화 및 SDN(소프트웨어 정의 네트워킹) 설정에 많이 사용됩니다.
Linux 컨테이너에 대한 네트워크 형성 및 대역폭 제어는 와 같은 기존 기술을 사용하여 달성할 수 있습니다 tc. 여기서는 이를 다루지 않겠습니다.
아래는 Docker가 IPTables 기능과 함께 Linux Bridge를 사용하여 격리된 컨테이너 네트워크를 만들고 컨테이너 포트를 노출하는 방법에 대한 빠른 데모입니다.
컨테이너 네트워킹 및 포트 포워딩
dig노출된 포트와 같은 DNS 도구와 함께 알파인 이미지를 사용할 것입니다 .
docker build -t so0k/envtest - << EOF
FROM alpine:latest
MAINTAINER Vincent De Smet <vincent.drl@gmail.com>
RUN apk --update add bind-tools && rm -rf /var/cache/apk/*
EXPOSE 80
EOF
테스트 네트워크 만들기
docker network create test
2개의 컨테이너를 실행하여 결과 Linux 구성을 시연합니다.
docker run --net test -dit --name host1 -P so0k/envtest sh
docker run --net test -dit --name host2 -P so0k/envtest sh
docker ps
Linux 브리지 및 IPtable 규칙 개요:
brctl show
sudo iptables -nvL
컨테이너 이미지 내에 노출된 각 포트에 대해 포트가 열렸습니다.
ss -an | grep LISTEN
기본 Docker 구성에서는 userland docker-proxy 프로세스가 사용됩니다.
ps -Af | grep proxy
많은 포트 를 열어야 하는 경우 주의하십시오 …
docker run --net test -dit --name prangetest -p 76-85:76-85 so0k/envtest sh
다음 프록시의 메모리 사용량:
ps -o pid,%cpu,%mem,sz,vsz,cmd -A --sort -%mem | grep proxy
Docker가 대체 규칙 과 함께 Linux 커널 '헤어핀' 전달 모드(커널 >=3.6)를 사용 하도록 강제 하는 userland docker-proxy를 비활성화 할 수 있습니다 . 이렇게 하면 네트워크 성능과 메모리 사용량이 향상됩니다.iptable
docker-proxy를 사용하지 않는 경우 - hairpin NAT 설정 없이 다른 컨테이너에 연결할 수 없습니다...
다음으로 Docker 네트워크 내에서 제공되는 몇 가지 간단한 "서비스 검색" 을 시연합니다.
docker exec -it host1 ping host2
docker exec -it host2 netstat -an
docker exec -it host1 dig host3 +noall +answer +stats
컨테이너가 이름 확인을 위해 Docker에 의해 어떻게 재구성되었는지 확인하십시오.
docker exec host2 cat /etc/resolv.conf
dns 프로세스가 컨테이너에 주입되었습니다.
docker exec -it host2 netstat -an
임베디드 DNS 구성에 대한 추가 정보 . 컨테이너 별칭을 생성할 수 있으며 필요한 경우 컨테이너 간에 개인 링크를 생성할 수 있습니다.
별도의 컨테이너 네트워크 간의 격리를 보여 드리겠습니다.
docker network create test2
docker run --net test2 -dit --name host3 -P so0k/envtest sh
docker run --net test2 -dit --name host4 -P so0k/envtest sh
이 네트워크에 대해 다른 Linux 브리지가 생성되었습니다.
brctl show
sudo iptables -nvL
첫 번째 네트워크의 컨테이너가 두 번째 네트워크의 컨테이너에 연결할 수 없는지 확인합니다. (이것을 실제로 확인하려면 호스트 이름 대신 실제 컨테이너 IP를 사용하십시오)
docker exec -it host1 ping host4
이름 확인은 2016년 1분기 Docker 1.10과 함께 도입되었습니다. Docker DNS 서버는 이전 버전과의 호환성을 위해 기본 Docker 브리지에 연결된 컨테이너에 노출되지 않습니다. (매개변수 없이 컨테이너를 실행하면 컨테이너 --net가 기본 브리지에 배치됨):
docker run -dit --name def-host1 -P so0k/envtest sh
docker run -dit --name def-host2 -P so0k/envtest sh
이름 확인 없음:
docker exec -it def-host1 cat /etc/resolv.conf
docker exec -it def-host1 hostname
docker exec -it def-host1 cat /etc/hosts
이러한 컨테이너가 서로를 찾아야 하는 경우 Docker 1.10 이전과 마찬가지로 링크를 사용하십시오.
docker run -dit --name def-host3 --link def-host1 -P so0k/envtest sh
docker exec -it def-host3 cat /etc/hosts
추가 포트를 공개적으로 노출하려는 경우 기본 브리지에 연결된 컨테이너의 예는 다음과 같습니다.
#forward packets from port 8001 on your host to port 8000 on the container
iptables -t nat -A DOCKER -p tcp --dport 8001 -j DNAT --to-destination ${CONTAINER_IP}:8000
앞에서 본 것처럼 위에서 생성한 모든 컨테이너의 cgroup 설정을 수정해 보겠습니다.
sudo systemd-cgls
보안
- AppArmor 및 jfrazelle/베인
- 세콤프
- 기능
현재 이 문서에는 예제가 제공되지 않습니다... 이것은 추가 연구 대상입니다.
용기의 종류
위의 구성을 감안할 때 컨테이너는 다음과 같이 3가지 유형으로 나눌 수 있습니다.
- 시스템 컨테이너 는 rootfs, PID, 네트워크, IPC 및 UTS를 호스트 시스템과 공유하지만 cgroup 내부에 있습니다.
- 애플리케이션 컨테이너 는 cgroup 내부에 있으며 호스트 시스템과의 격리를 위해 네임스페이스(PID, 네트워크, IPC, chroot)를 사용합니다.
- Pod 는 호스트 시스템과의 격리를 위해 네임스페이스를 사용하지만 rootfs를 제외하고 PID, 네트워크, IPC 및 UTS를 공유하는 하위 그룹을 만듭니다.
참고 로 Docker 상단의 현재 Pod 구현 은 하위 그룹이 네임스페이스를 공유할 수 있도록 하는 해결 방법이 필요하므로 차선책 입니다(이는 기본적으로 pid 1인 절전 컨테이너를 통해 구현됨). 이상적으로는 systemd와 같은 것이 PID 1로 사용되어 하위 그룹과 chroot 간에 네임스페이스를 공유하여 rootfs를 분리합니다.
이미지 및 레이어
자신이 만든 이미지 또는 다른 사람이 만든 이미지는 Docker Registries 에 저장됩니다 . 이미지를 업로드하거나 다운로드하는 공개 또는 비공개 저장소입니다. Docker 레지스트리는 Docker의 배포 구성 요소입니다.
레지스트리 사용에는 3가지 선택 사항이 있습니다.
- 퍼블릭 클라우드 호스팅 레지스트리. 도커 허브 는 도커 클라이언트에서 사용하는 기본 레지스트리이자 공식적으로 유지 관리되는 도커 이미지의 소스이지만 Quay.io 와 같은 대안이 있습니다 . 빠른 Docker 채택을 위해 제한된 개인 리포지토리를 만들거나 구입할 수 있습니다.
- 상용으로 제공되는 Trusted Docker Registry 를 통해 고급 구성 옵션, 로깅, 사용량 및 시스템 상태 메트릭 등을 제공 하는 온프레미스 레지스트리
- 공식 오픈 소스 Docker 레지스트리 를 기반으로 하는 자체 호스팅 레지스트리 입니다. 이것은 스스로 완벽하게 설정할 수 있는 완전한 기능의 레지스트리이며 Docker Trusted Registry가 구축되는 기반이지만 고급 모니터링 및 액세스 제어를 제공하지 않으며 수동 유지 관리가 필요합니다.
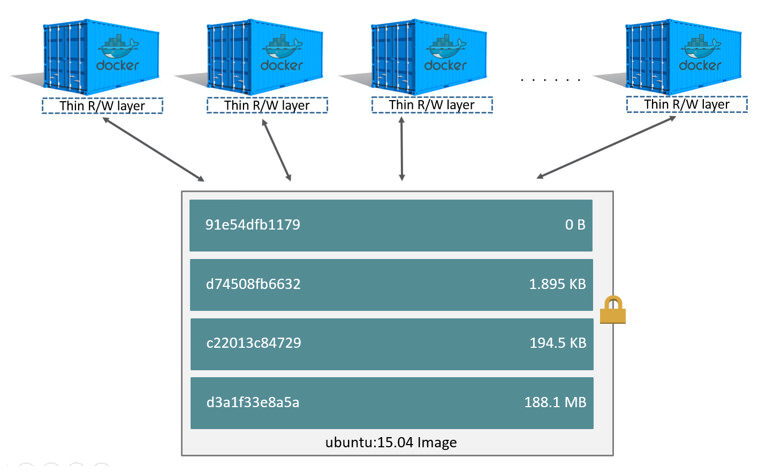
각 Docker 이미지는 파일 시스템 차이를 나타내는 읽기 전용 계층 목록을 참조합니다. 레이어는 컨테이너의 rootfs에 대한 기반을 형성하기 위해 서로의 위에 쌓입니다.

컨테이너가 시작되면 Docker 엔진은 chrootLXC와 유사하게 컨테이너 파일 시스템 격리를 위해 rootfs 및 사용을 준비합니다. Docker 엔진의 큰 혁신 중 하나는 Copy-On-Write 파일 시스템을 활용하여 rootfs 준비 속도를 크게 높이는 개념이었습니다.
기록 중 복사
Docker 이전에 LXC는 컨테이너를 생성할 때 FileSystem의 전체 복사본을 생성했습니다. 이것은 느리고 많은 공간을 차지합니다.
Docker 는 컨테이너 를 생성 할 때 이미지 레이어의 기본 스택 위에 쓰기 가능한 새 레이어를 추가합니다 . 이 레이어를 종종 "컨테이너 레이어"라고 합니다.
새 파일 쓰기, 기존 파일 수정 및 파일 삭제와 같이 실행 중인 컨테이너에 대한 모든 변경 사항은 쓰기 가능한 얇은 컨테이너 계층에 기록됩니다.
전체 rootfs를 복사하지 않음으로써 Docker는 컨테이너가 사용하는 공간의 양을 줄이고 컨테이너를 시작하는 데 필요한 시간도 줄입니다. 아래는 여러 컨테이너와 그 "컨테이너 계층"을 보여주는 다이어그램입니다.
Union File Systems는 다음과 같은 스토리지 기능을 제공합니다.
- 레이어링
- 기록 중 복사
- 캐싱
- 디핑
Docker에 스토리지 플러그인을 도입하면 Copy-On-Write 기능에 대해 다음과 같은 다양한 옵션을 사용할 수 있습니다.
- 오버레이FS(CoreOS)
- AUFS(우분투)
- 장치 매퍼(RHEL)
- btrfs(차세대 RHEL)
- ZFS (차세대 Ubuntu 릴리스)
언제 선택해야 하는지에 대한 간략한 개요는 여기에 제공되며 자세한 내용은 우수한 Docker 문서 에 있습니다.
- AUFS: PaaS 유형 작업 :
찬성범죄자
| 안정적인 | 높은 쓰기 활동 |
| 생산 준비 | 메인라인 커널이 아님 |
| 좋은 메모리 사용 | |
| 원활한 도커 경험 |
Aufs3 기본값 및 현재 Ubuntu에 권장됨
- devicemapper(direct-lvm): Paas 유형 작업 :
찬성범죄자
| 안정적인 | ?? |
| 생산 준비 | |
| 메인라인 커널에서 | |
| 원활한 도커 경험 |
RHEL의 프로덕션 환경을 위한 가장 안정적인 구성이지만 기본 설정을 덮어쓰려면 데몬 플래그가 필요합니다.
- devicemapper(루프): 랩 테스트 - RHEL의 Docker에서 기본값이며 프로덕션에는 권장되지 않습니다.
찬성범죄자
| 안정적인 | 생산 |
| 메인라인 커널에서 | 성능 |
| 원활한 도커 경험 |
루프백 마운트된 스파스 파일을 사용하면 추가 코드 경로와 오버헤드가 I/O가 많은 워크로드에 적합하지 않습니다.
- OverlayFS: 랩 테스트
찬성범죄자
| 안정적인 | 컨테이너 이탈 |
| 메인라인 커널에서 | |
| 좋은 메모리 사용 |
미래로 환영받는 CoreOS의 기본값이지만 덜 성숙하고 잠재적으로 덜 안정적입니다...
하지만... 컨테이너 생성/제거 비율이 높으면 ionode 문제가 발생하므로 빌드 풀에는 좋지 않습니다..
- Btrfs: 풀 빌드
찬성범죄자
| 메인라인 커널에서 | 높은 쓰기 활동 |
| 컨테이너 이탈 |
컨테이너 런타임 개요
이 섹션의 목표는 다른 컨테이너 런타임(과거의 일부, Docker에 대한 일부 대안 및 향후 구현)을 사용하는 것입니다.
LXC
libcontainer가 대체할 때까지 Docker에서 원래 백엔드로 사용했습니다.
- 설치 중:
install bridge-utils libvirt lxc lxc-templates
- 사용 가능한 명령
lxc-attach lxc-config lxc-freeze lxc-start lxc-usernsexec
lxc-autostart lxc-console lxc-info lxc-stop lxc-wait
lxc-cgroup lxc-create lxc-ls lxc-top
lxc-checkconfig lxc-destroy lxc-monitor lxc-unfreeze
lxc-clone lxc-execute lxc-snapshot lxc-unshare
- busybox의 LXC 기반 컨테이너를 사용하는 빠른 가이드
wget https://www.busybox.net/downloads/binaries/busybox-x86_64 -o busybox
chmod a+x busybox
PATH=$(pwd):$PATH lxc-create -t busybox -n mycontainer
lxc-start -d -n mycontainer
lxc-console -n mycontainer # (use CTRL-A Q to exit console mode)
lxc-stop -n mycontainer
lxc-destroy -n mycontainer
흥미로운 읽기: OverlayFS 및 Ansible을 사용하는 Docker가 없는 Linux 컨테이너 .
LXC 프로젝트는 2014년 11월부터 LXD 라는 Docker 데몬과 유사한 사용자 친화적인 데몬을 작업하고 있습니다.
시스템 nspawn
원래 Systemd init 시스템을 디버그하기 위해 만들어졌지만 향후 버전은 OS의 핵심에 더 통합될 예정입니다(컨테이너를 OS에 기본으로 만들기 위한 가장 낮은 수준의 최소 접근 방식).
CoreOS Toolbox는 systemd-nspawn을 사용하고 CoreOS rkt는 그 위에 빌드됩니다.
- 설치 중:
모든 최신 Linux 배포 릴리스에 포함..
- 사용 가능한 명령
systemd-analyze systemd-delta systemd-nspawn
systemd-ask-password systemd-detect-virt systemd-run
systemd-cat systemd-cgls systemd-loginctl
systemd-sysv-convert systemd-cgtop systemd-machine-id-setup
systemd-coredumpctl systemd-notify systemd-tty-ask-password-agent
systemd-inhibit systemd-stdio-bridge systemd-tmpfiles
systemdctl machinectl hostnamectl journalctl
- systemd-nspawn을 사용한 컨테이너 배포에 대한 빠른 가이드
# Create an Image (fedora)
sudo yum -y --releasever=7 --nogpg --installroot=/mycontainers/centos7 \
--disablerepo='*' --enablerepo=fedora \
install systemd passwd yum fedora-release vim-minimal
# Change the root password in the image (through a shell in the rootfs)
sudo systemd-nspawn -D /mycontainers/centos7
passwd
exit
# Start the container as if booting into the container image
sudo systemd-nspawn -bD /mycontainers/centos7 -M mycontainer --bind /from/host:/in/container
# Get list of containers registered with machine
machinectl list
machinectl status mycontainer
# log into the container
machinectl login mycontainer
# or enter the running namespace
nsenter -m -u -i -n -p -t $PID
참조 - Docker 없는 Docker 참조 - Rubber Docker Workshop - Prep Slides
실행C
Docker libcontainerEngine에서 파생되어 현재 Docker Engine의 핵심인 OCI 호환 가능
- runC 설치
apt-get update && apt-get install libseccomp2
curl -Lo /usr/local/bin/runc https://github.com/opencontainers/runc/releases/download/v0.0.8/runc-amd64
chmod +x /usr/local/bin/runc
- 구축 및 설치
Docker 1.10 이미지가 있는 Digital Ocean Ubuntu 14.04:
빌드 종속성:
apt-add-repository -y ppa:evarlast/golang1.4
apt-get update
apt-get install make gcc g++ libc6-dev libseccomp-dev golang
절차
cd ~
git clone https://github.com/opencontainers/runc
cd runc
GOPATH="$(pwd)" PATH="$PATH:$GOPATH/bin" make
make install
cd ~
- 사용 가능한 명령
checkpoint pause
delete restore
events resume
exec spec
kill start
list help
- runcDocker 배송 을 사용한 컨테이너 배포에 대한 빠른 가이드 입니다.
- Docker 엔진은 우리를 위해 뒤에서 아래의 모든 작업을 수행하고 제공하는 편안함의 수준을 높이 평가합니다.
# Download an OCF compliant image (using docker for example)
docker pull busybox
# Create busybox/rootfs
mkdir -p busybox/rootfs
# Flatten the image layers & copy to rootfs
tmpcontainer=$(docker create busybox)
docker export $tmpcontainer | tar -C busybox/rootfs -xf -
docker rm $tmpcontainer
# Generate container spec file
cd busybox/
runc spec
# start the container
runc start test
# confirm we are now in busybox container
/bin/busybox
ps -a
또는 tianon의 스크립트 download-forzen-image-v2.sh 를 사용하여 레지스트리에서 이미지 레이어를 다운로드합니다.
또는 debootstrap…
cd ~
apt-get install debootstrap
mkdir -p debian_wheezy/rootfs
debootstrap --arch=amd64 wheezy debian_wheezy/rootfs
cd debian_wheezy
runc spec
runc start debian
시작 후 후크(in config.json)를 사용하여 추가 바이너리/스크립트를 호출하여 컨테이너에 대한 가상 브리지 및 veth 쌍 및 iptable 규칙 설정과 같은 작업을 수행할 수 있습니다.
도커 API
이 섹션의 목표는 알림 시스템의 일부를 활용하기 위해 다양한 Docker 구성 요소에 연결하는 방법에 대한 개요를 제공하는 것입니다. 이것은 순전히 Docker 위에 구축된 플랫폼을 이해하려는 엔지니어의 갈증을 해소하기 위한 것입니다.
많은 기존 플랫폼이 이미 오케스트레이션 계층을 제공하고 있으며 이러한 이벤트를 사용하여 자체 솔루션을 구현하기 전에 기존 솔루션을 조사하는 것이 좋습니다.
도커 엔진
사용 사례:
- jwilder/docker-gen - 간단한 구현용도: fsouza/go-dockerclient
- 코드: Docker 클라이언트를 등록하고 리스너에 이벤트를 전달하는 방법 (Golang)
- docker-gen은 이러한 API를 사용하고 컨테이너 메타 데이터를 템플릿에 노출하는 작은 유틸리티입니다. 템플릿이 렌더링되고 선택적 알림 명령을 실행하여 서비스를 다시 시작할 수 있습니다.
- docker-gen을 사용하여 Nginx 구성 파일을 자동으로 생성하고 변경될 때 nginx를 다시 로드할 수 있습니다. 도커 로그 관리에도 동일한 접근 방식을 사용할 수 있습니다.
- ehazlett/interlock - 확장 기능이 있는 복잡한 구현용도: samalba/dockerclient
- 코드: TTL 캐시를 사용하여 확장을 다시 로드하는 방법
- Swarm을 사용하는 동적 이벤트 기반 확장 시스템. 확장에는 동적 로드 밸런싱을 위한 HAProxy 및 Nginx가 포함됩니다.
- 모니터링 docker stats및 그 뒤에 있는 API? c고문? 모니터링에 대한 추가 정보: https://www.youtube.com/watch?v=sxE1vDtkYps&feature=youtu.be
도커 레지스트리
웹훅을 통한 알림:

사용 사례: 도관
Conduit는 웹훅을 수신하는 엔드포인트를 노출합니다(예: Docker Hub에서). 후크를 수신하면 Conduit은 새 이미지를 가져오고 업데이트된 이미지에서 새 컨테이너를 배포한 다음 원래 컨테이너를 제거합니다.
도커 작성
표준 출력을 통해
참조: Docker Compose 이벤트 문서 및 PR
샘플 요지(PR에서):
#!/bin/bash
set -e
function handle_event() {
local entry="$1"
local action=$(echo $entry | jq -r '.action')
local service=$(echo $entry | jq -r '.service')
local hook="./hooks/$service/$action"
if [ -x "$hook" ]; then
"$hook" "$entry"
fi
}
docker-compose events --json | (
while read line; do
handle_event "$line"
done
)
컨테이너 형식 폭발
Docker가 컨테이너를 쉽게 만들면서 Docker 표준에 대한 엄청난 기여와 함께 생태계가 등장했습니다.
그러나 컨테이너 인프라 내 각 계층의 정확한 요구 사항 및 책임에 대해 서로 다른 의견이 존재하며, 파이의 일부를 차지하려는 많은 대기업과의 격차가 예상되었습니다.
이 섹션의 목표는 미래 및 향후 인프라를 살펴보는 것입니다. 이 중 Docker는 현재(2015년 말) 가장 성숙하고 초보자가 시작하기에 가장 쉽습니다.
컨테이너(알파) - Docker 제공
containerd.tools - 도커 데몬을 보다 발전된 OCI 호환 데몬으로 회전하여 runC를 제어하는 것을 참조하십시오 .
GRPC 사용
모바일과 HTTP/2를 최우선으로 하는 고성능 오픈 소스 일반 RPC 프레임워크입니다.
Containerd는 Docker Engine의 향후 버전에서 컨테이너를 관리할 배관 구성 요소입니다.
curl -Lo /usr/local/bin/containerd https://github.com/docker/containerd/releases/download/0.0.5/containerd
curl -Lo /usr/local/bin/ctr https://github.com/docker/containerd/releases/download/0.0.5/ctr
curl -Lo /usr/local/bin/containerd-shim https://github.com/docker/containerd/releases/download/0.0.5/containerd-shim
chmod +x /usr/local/bin/{containerd,ctr,containerd-shim}
nohup containerd >/dev/null 2>&1 &
Docker를 사용하여 허브에서 가져오기 위해 redis 이미지 만들기
mkdir -p redis/rootfs
docker pull redis
tmpredis=$(docker create redis)
docker export $tmpredis | tar -C redis/rootfs -xf -
docker rm $tmpredis
OCI 번들 준비:
생성하다config.json
runc spec
편집 config.json:
- 터미널: 거짓
- uid 및 guid 채우기
- set args: “redis-server”, “–bind”, “0.0.0.0”
- 올바르게 설정cwd
편집 runtime.json:
- network테스트를 위해 localhost에서 쉽게 연결할 수 있도록 지금은 네임스페이스를 제거하십시오 …
리포지토리 에서 보기 config.json및runtime.jsoncontainerd
또는 jfrazelle/ riddler를 사용하여 Docker 컨테이너 정의에서 번들 생성
OCI(OpenContainers 이니셔티브)
OCI는 현재 런타임만 다루고 있습니다.
이미지 정의 방법을 다루지 않고 신원 확인을 다룰 수 있음
Docker는 runC에서 기술 드래프트 및 OCI 구현을 제공했습니다(프로세스에서 libcontainer를 runC로 이동).
- OCI? (레이어의 단순 tarball+푸시되는 메타데이터)
appc 노력의 배후에 있는 개인들은 OCI의 기술 리더십에 합류하고 있으며, 우리의 의도는 기존 컨테이너 형식과 호환되는 공통 형식을 향해 작업하고 모든 요소의 최고의 요소를 결합하는 미래 사양에서 작업하는 것입니다. 기존 컨테이너 노력.
컨테이너 이미지 형식 및 런타임에 대한 공식 사양("OCI 사양")을 생성 및 유지하여 인공적인 기술적 장벽 없이 모든 주요 호환 운영 체제 및 플랫폼에서 호환 컨테이너를 이식할 수 있습니다.
OCI의 이면에 있는 아이디어는 널리 배포된 런타임 및 이미지 형식 구현을 docker에서 가져와 appc의 정신으로 개방형 표준을 구축하는 것이었습니다.
AppC - CoreOS별
- 초기에 Docker 이미지 형식을 기반으로 하는 이미지 형식(ACI) 및 ID
- 컨테이너 서명
- 이미지를 쉽게 저장하고 이미지가 있는 위치를 찾을 수 있는 검색 메커니즘(기본 레지스트리 없음, 특수 레지스트리 없음)
- 런타임 환경: 이미지 실행 시 정의된 동작.
- 툴링: 멋진 툴링이 필요하지 않습니다. 예를 들어 명령줄 도구를 사용하여 쉽게 빌드 tar하고 gzip서명 gpg할 수 있습니다.
이미지 형식
ACI(ref AMI)는 지정된 앱을 실행하는 데 필요한 모든 파일과 메타데이터를 포함해야 합니다.
Docker와의 주목할만한 차이점: ACI는 탑재 지점을 지정해야 합니다…
Docker는 볼륨을 지정할 필요가 없으며 유연성을 제공하지만 이미지 매니페스트를 읽고 필요한 모든 탑재 지점을 알 수는 없습니다. AppC는 런타임에 볼륨을 강제로 정의할 수 있으며 생략된 경우 실패합니다.
- rootfs: Docker 이미지 형식과 동일합니다. 기존 시스템일 수 있습니다. 로 생성할 수 있습니다 docker build. 기본 시스템 도구 Debian/Redhat 도구로 빌드하여 chroot에서 전체 시스템을 빌드할 수 있습니다.
- 이미지 매니페스트: AppC 리포지토리에 정의된 모든 정의된 필드입니다. 요점은 레이블의 개념을 사용하여 커널 요구 사항(컨테이너가 커널을 공유함)과 마운트 지점 정의에 대한 명시적 요구 사항을 정의하는 데 사용할 수 있다는 것입니다.
이미지는 콘텐츠 주소 지정이 가능하고 레이어를 공유해야 합니다.
발견 메커니즘
ACI 이름을 다운로드 가능한 이미지로 변환합니다. 모든 ACI에는 분리된 서명이 있어야 하며 확인 프로세스를 수행해야 합니다.
규칙에 따라 런타임에 템플릿을 사용할 수 있습니다.
메타데이터 끝점을 검색하여 검색 메커니즘을 검색할 수 있습니다(예: 이미지를 배포하기 위해 bittorrent와 같은 다른 프로토콜을 사용하려는 경우).
런타임 환경
AppC는 호스트에서 ACI가 실행되는 방식을 정의합니다. 기본 개념은 컨테이너 내에서 여러 이미지를 실행하고 컨테이너 내 각 이미지 인스턴스에 대한 복구 정책을 정의하는 것입니다.
다음을 정의합니다.
- 파일 시스템 레이아웃: Pod = 컨테이너 컬렉션을 단일 실행 단위로 구성하는 기능의 개념을 사용합니다.
- 볼륨: 모든 마운트 포인트를 지정하기 위한 특정 요구 사항이 있으며 이를 수행하는 것이 실행자 작업입니다.
- 네트워킹(CNI): 네트워크 플러그인
- 리소스 격리자: 컨테이너를 실행할 때 모든 cgroup을 정의해야 합니다.
- 로깅: 런타임은 모든 파드와 파드에서 실행되는 컨테이너에 대한 로그를 보유해야 합니다.
압형
, , … actool_ _actool buildactool cat-manifestactool validate
actool또는 위에 나열된 명령줄 도구 를 사용하여 빌드할 수 있습니다 .
런타임은 즉시 Docker 이미지를 변환하거나 Docker 이미지 변환, 패키지 변환 등의 도구를 사용할 수 docker2aci있습니다 deb2aci.
이미지 콘텐츠 확인, 초기 순진한 구현은 분리된 gpg 서명(기본적으로 인터넷을 통해 물건을 다운로드할 때 예상하는 공개 서명된 해시를 정의함)을 사용하는 것이므로 이상적이지 않습니다.
다가오는 이미지 검증 표준은 Notary를 통해 Docker에서 채택한 TUF(업데이트 프레임워크)입니다. TUF는 yum index/apt repo와 유사합니다. 기본적으로 다운로드 후 확인을 위한 암호화 메타데이터와 함께 레지스트리에 있는 모든 이미지의 메타데이터를 제공하는 JSON 파일입니다.
AppC의 기존 구현
rkt
3단계로 작동:
- stage0: 이미지 가져오기, 압축 풀기, 확인, ..
- stage1: 이미지 실행(nspawn 사용) - 현재 systemd init 시스템을 시작하고 프로세스는 데몬을 통하지 않고 할당된 cgroup 아래 프로세스 트리에서 직접 실행됩니다.
- 2단계: 아이솔레이터 적용
'K8S > Docker' 카테고리의 다른 글
| Docker forwarding 추가 및 중간에 변경하는법 (0) | 2022.11.14 |
|---|---|
| docker 컨테이너 설정 파일찾기(for windows) (0) | 2022.11.14 |
| docker-compose 에러: Operation CREATE USER failed for 'root'@'% (0) | 2022.09.29 |
| docker-compose 에러:You might be seeing this error because you're using the wrong Compose file version. Either specify a supported version (0) | 2022.09.28 |
| Docker 설치 (for windows) (0) | 2022.08.22 |


댓글