학습?
- 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것
여기서는 신경망이 학습할수 있도록 해주는 지표인 손실 함수를 소개합니다.
학습의 목표는 이 손실함수의 결과값을 작게 만드는 가중치 매개변수를 찾는것이다.
신경망은 데이터를 보고 학습할수 있다.
즉, 가중치 매개변수의 값을 데이터를 보고 자동으로 결정한다. (층이 깊은 딥러닝은 수억개가 된다.)
Feature(특징) : 입력데이터에서 본질적인 데이터를 정확하게 추출할 수 있도록 설계된 변환기.
MachineLearning : 모아진 데이터로부터 규칙을 찾아내는 역할을 기계가 담당
- 입력값을 벡터로 변환할 때 사용하는 특징은 여전히 사람이 한다.(안해도 되지만 하면 좋은결과)

딥러닝을 end-to-end machine learing이라고도 한다. ( 기계가 입력부터 출력까지 다한다는뜻)
Training data(훈련데이터), test data(시험데이터)
- 범용적으로 사용할수 있는 모델을 만들기위해 데이터를 훈련데이터와 시험데이터 두개로 나누어 학습한다.
Overfitting(오버피팅) : 한 데이터에 지나치게 최적화 된 상태 (이것을 피해야한다.)
손실함수
신경망은 하나의 지표를 기준으로 최적의 매개변수 값을 탐색한다. 신경망 학습에서 사용하는 지표는 손실함수이다.
손실함수는 임의의 함수를 사용할수 있지만 보통 평균 제곱오차와 교차 엔트로피 오차를 사용한다.
성능의 나쁨을 나타내는 지표로 신경망이 훈련데이터를 얼마나 잘처리하지 못하느냐를 나타낸다.
평균제곱오차(MSE - mean squarer error)
가장 많이 쓰이는 손실함수


yk는 신경망의 출력(신경망의 추측값), tk는 정답레이블, k는 데이터의 차원수 이다.
ex) tk에 정답레이블(원-핫 인코드), yk에 소프트 맥스함수 출력값
예시를 들어보면

추정결과가 평균제곱오차의 결과값이 더 작은 첫번째 추정값이 정답에 더 가깝다고 볼수있다.
교차 엔트로피 오차(CEE - Cross Entropy Error)

log는 밑이 e인 자연로그이고 tk,yk는 평균 제곱오차와 마찬가지로 정답레이블, 신경망의 출력이다.
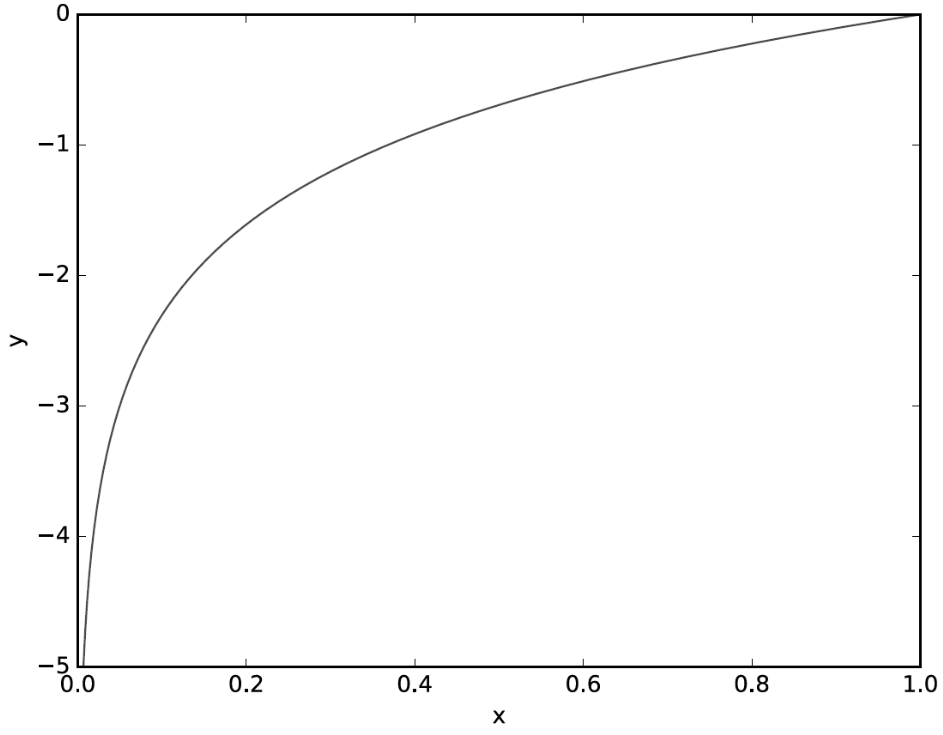
그래프를 보면 x=1일때 y는 0이되고 x=0 에 가까울수록 y의 값을 점점 작아진다.
이처럼 위 식도 정답에 해당하는 출력(y)이 커질수록 0 에 가까워 지다가 출력이 1일때 0이 된다.
반대로 정답일때의 출력이 작아질수록 오차는 커진다.(즉 0에 가까울수록 정답! 이다.)
이것도 코드화 하여 예시를 들어보면
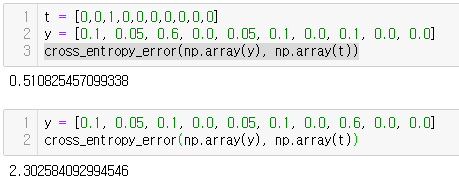
- 정답이 아닌 나머지 모두는 tk가 0이므로 logyk와 곱해도 0이되어 결과에 영향을 주지 않는다.교차 엔트로피 오차 함수 코드화

미니배치 학습
기계학습 문제는 훈련 데이터를 사용해 학습한다.
즉, 훈련데이터에 대한 손실함수의 값을 구하고, 그값을 줄여주는 매개변수를 찾아낸다.
지금까지는 한개의 데이터에 대한 손실함수를 고려햇으나, 이제 훈련데이터 모두에 대한 손실함수의 합을 구하는 방법을 고려해보자!

N은 데이터의 갯수고 tnk는 n번째 데이터의 k번재 값을 의미한다(ynk도 마찬가지)
마지막에 N을 나누어 정규화, 즉 평균 손실함수를 구하는것이다.( 평균구한다고 생각하면 된다.)
근데 MNST데이터셋은 60,000개 라 엄청나게 오래걸릴듯하다.
그래서 일부를 추출하여 학습을 한다. 이것을 미니배치 학습이라고 한다.
훈련데이터에서 지정한수의 데이터를 무작위로 골라내는 코드를 작성해보자

x_train, t_train의 shape(크기, 모습)을 보면
훈련데이터는 60000개, 입력데이터는 784개
정답레이블은 10줄짜리 데이터 라는것을 알수있다.

(배치용) 교차 엔트로피 오차 구현하기


손실함수를 사용하는 이유
그런데 정확도를 사용하면 되는데 굳이~~ 손실함수를 사용하는 이유가 뭘까? 라는 의문이 든다.
어차피 같은 오차값을 구하는것 아닌가?
그것은 매개변수(가중치와 편향)를 탐색할때 손실함수의 값을 가능한 작게하는 매개변수의 값을 찾는 과정을 보면 알수 있다.
이때 매개변수의 미분을 계산하고 그 미분값을 단서로 매개변수의 값을 서서히 갱신하는 과정을 반복한다.
정확도를 지표로 하면 미분값이 대부분의 장소에서 0이 되버리기 때문이다.
0이 되는게 왜 문제가 되냐면 매개변수를 조정해서 개선이 되어야 하는데 정확도 같은경우는 0이 되어서 더이상 조정할게 없다. 손실함수 같은경우는 X.123124235 이런식으로 연속적인 값으로 나온다.
계단함수를 사용하지 않고 시그모이드 함수를 신경망에 사용하는 이유도 이와 같다.
수치미분(numerical dfferentiation)
미분은 정규 교육과정에서 다 배웠는데 굳이? 다시 배우는 이유가 있나 했는데 이유가 있다!


이게 반올림 오차(rounding error)라는 문제를 일으켜서 그냥 쓰면 안된다.
반올림오차는 작은값이 생략되어 최종 계산 결과에 오차가 생기게 된다(ex. 0.1513548에서 뒷부분이 생략됨)
파이썬에서 구동되는것을 보면

그다음은 차분(두점에서의 함수값들의 차이)에 관한것인데
x+h와 x의 사이의 함수f의 차분을 계산하지만 여기에는 오차가 있다.

진정한 접선은 x위치의 함수 기울기에 해당하지만 위에서 구한 미분은 (x+h)와 x사이의 기울기에 해당한다.
그래서 서로 일치하지 않아 오차가 발생한다. 이유는 h가 무한히 0으로 될수가 없기 때문이다.
개선 방법
- 소수점 자리를 10^-4로 정한다.
- x를 중심으로 그전후의 차분을 계산한다.(전방,후방 차분을 둔다.)

이처럼 아주 작은 차분으로 미분하는 것을 수치 미분이라 한다.
편미분 - 변수가 여럿인 함수에 대한 미분


기울기
근데 편미분은 갑자기 왜 한걸까?
편미분에 나왔던 함수를 미분하여 그림으로 표현해보자

보면 기울기가 가장 낮은 장소를 가리킨다.
즉, 기울기는 각지점에서 낮아지는 방향을 가리킨다는것을 알수있다.
기울기가 가리키는 쪽은 각장소에서 함수의 출력 값을 가장 크게 줄이는 방향

경사법(경사 하강법)
신경망은 최적의 매개변수(가중치와 편향)를 학습시에 찾아야 한다.
여기서 최적이란 손실함수가 최소값이 될 때의 매개변수 값이다.
이러한 최소값을 찾기위하여 기울기를 활용 할 것이다.
그런데 꼭 기울기가 가리키는 곳이 함수의 최소값이 있는지 확실하지가 않다.
그래도 기울기가 적어지는 방향은 최소값으로가는 방향이라는것은 알수있다.
이 점을 이용하여 경사법이라는 것을 사용한다.
경사법이란 현위치에서 기울어진 방향으로 일정한 거리만큼 이동하는것을 반복하는것을 말한다.
(최소값을 찾을땐 경사하강법, 최대값을 찾을땐 경사 상승법 -> 우리는 최소값찾으므로 경사하강법사용)
이것을 수식으로 나타내면

여기서 η 는 갱신하는 양을 나타낸다. 신경망 학습에서는 학습률(learning rate)이라고 한다.
한 번의 학습으로 얼마만큼 학습해야 할지, 즉 매개변수 값을 얼마나 갱신하느냐를 결정하는 것이 학습률이다.
여기서 변수(편미분값) 이 늘어도 같은식으로 갱신하게 된다.
또한 학습률 값은 0.01 이나 0.001등 미리 특정값으로 정해야 한다.
너무 크거나 작으면 최적값을 찾아가는데 오래걸리거나 못찾게 된다( 효율성이 떨어진다)

함수의 기울기를 구하고, 그기울기에 학습률을 곱한값으로 갱신 처리를 step_num번 반복한다.

거의 정확한 결과를 얻었다
이것을 그림으로 나타내면

하이퍼파라미터
가중치와 편향 같은 신경망의 매개변수와는 성질이 다른 매개변수
신경망의 가중치 매개변수는 훈련데이터와 학습알고리즘에 의해 자동으로 획득되는 매개변수지만
하이퍼파라미터는 사람이 직접 설정하는 매개변수
이 값도 시험을 통해 잘학습하는 값을 과정을 거쳐야한다.
신경망에서의 기울기
기울기에 대해 알아 보았으니 이제 이것을 신경망에서 적용해보자
예시로 형상이 2X3, 가중치가 W, 손실함수가 L인 신경망을 만들어보자.
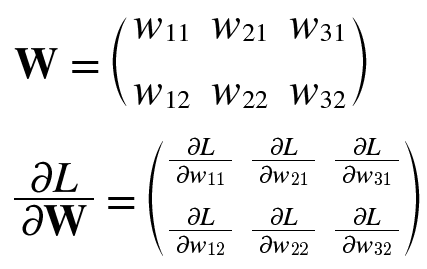

전에 구성했던 softmax와 cross_entropy_error 메서드를 이용한다. numerical_gradient메서드도 사용
simpleNet 클래스는 2x3인 가중치 매개변수 하나를 인스턴스 변수로 갖는다.
메서드는 2개인데 예측을 수행하는 predict, 손실함수의 값을 구하는 loss 이다.(x는 입력, t는 정답레이블이다.)


여기서 손실함수를 줄이려면 w11은 음의방향으로, w23은 양의방향으로 하면 줄일수 있다는것을 알수있다.

'DATA Science > DeepLearing from scratch' 카테고리의 다른 글
| 오차역전파법 (0) | 2021.05.14 |
|---|---|
| 신경망 학습 - 학습 알고리즘 구현 (0) | 2021.05.13 |
| 신경망 (0) | 2021.05.12 |
| 퍼셉트론 (0) | 2021.05.11 |
| Matplotlib - 그래프 (0) | 2021.05.11 |




댓글